

Is your AI budget bleeding out through “Dark Context”? In 2026, we’ve moved past the novelty of Large Language Models (LLM). We are now in the era of Agentic Orchestration, where Claude 4.6 is capable of managing entire repositories and complex supply chains. But with great power comes a massive “Invisible Tax”: Token Bloat.
If you are still using Claude the way you did in 2024—sending massive blocks of text without caching or context hygiene—you are likely overpaying by 400-600%.
The secret to scaling AI isn’t just a bigger budget; it’s a smarter Token Strategy. Read my full deep dive on how the world’s top AI architects are optimizing Claude for maximum intelligence and minimum waste.
The Invisible Tax: A Guide to Preventing and Optimizing Claude Token Usage
For the modern enterprise, the “Context Window” has become the new boardroom. We aren’t just chatting with Claude anymore; we are feeding it entire codebases, multi-year project plans, and 1,000-page regulatory documents. With the arrival of Claude 4.6 and its standard 1-million-token context window, the temptation to “just throw everything in” is higher than ever.
However, in 2026, token density is the new business efficiency. Every redundant token is a micro-tax on your ROI. Experts have moved away from “brute-force” prompting toward a sophisticated methodology of Context Hygiene and Strategic Caching. This article breaks down the 2026 blueprint for optimizing Claude usage to ensure you are paying for insight, not just ink.
1. The Tiered Intelligence Strategy: Choosing Your Weapon
The first step in token optimization isn’t technical—it’s strategic. In the 2026 Anthropic ecosystem, the “one-size-fits-all” model is dead. High-performing teams use a Multi-Model Orchestration strategy.
- Claude 4.5 Haiku: The “Workhorse.” Best for routine formatting, simple data extraction, and sub-agent coordination. Using Opus for a task Haiku can solve is the architectural equivalent of using a private jet to get groceries.
- Core Capabilities: Routine Formatting, Data Extraction, Simple Classification, and Sub-Agent Routing.
- Pricing: High-Volume $1 / $5 per 1M tokens.
- Strategic Role: This is your high-volume workhorse, handling 60% of routine workflows.
- Claude 4.6 Sonnet: The “Gold Standard.” It balances state-of-the-art reasoning with mid-tier pricing. 90% of coding and complex analysis tasks should live here.
- Core Capabilities: Standard Logic, Complex Coding, Structured Data Analysis, and Technical Draft Writing.
- Pricing: Gold-Standard $3 / $15 per 1M tokens.
- Strategic Role: This is your primary workflow engine. 30% of your complex reasoning and development tasks live here.
- Claude 4.6 Opus: The “Philosopher-Scientist.” Reserved for deep architectural decisions and cross-domain synthesis.
- Core Capabilities: Multi-variable Synthesis, Deep Architectural Planning, Philosophic/Ethical Analysis, and Unsupervised Reasoning.
- Pricing: Premium $5 / $25 per 1M tokens (Input/Output).
- Strategic Role: Reserved for the 10% of high-stakes, multi-domain decisions where reasoning accuracy is paramount and cost is secondary.
2. Prompt Caching: The 90% Discount
The most significant advancement in 2026 AI economics is Prompt Caching. Traditionally, every time you sent a message in a long conversation, you re-paid for every single token that came before it. In 2026, that is a cardinal sin.
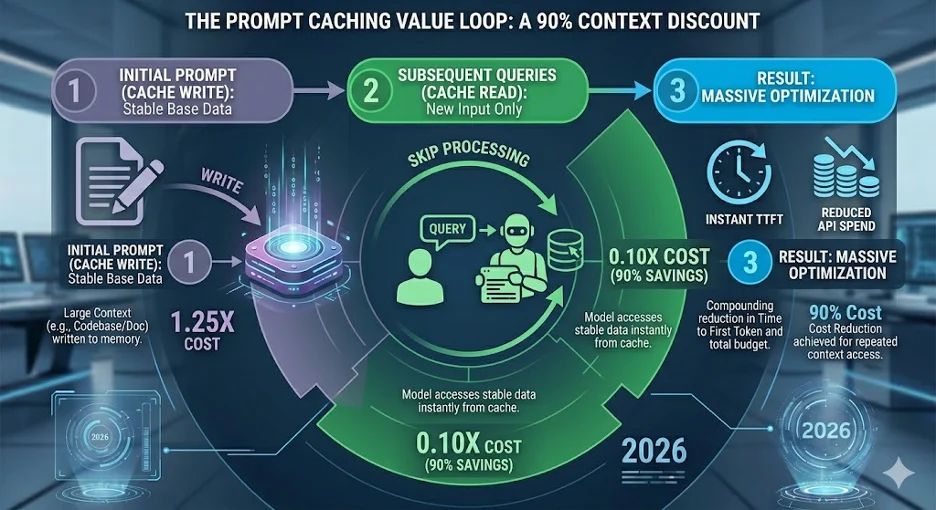
Anthropic’s Automatic Caching now moves the cache point forward as conversations grow. By placing stable content—System Instructions, Brand Guides, and Large Context—at the beginning of the prompt, users can see up to a 90% reduction in costs for multi-turn sessions.
3. Context Window Hygiene: The “Clear & Compact” Rules
The biggest killer of token efficiency is “The Obese Thread.” Long-horizon conversations naturally accumulate “Dark Context”—stale information and redundant code samples.
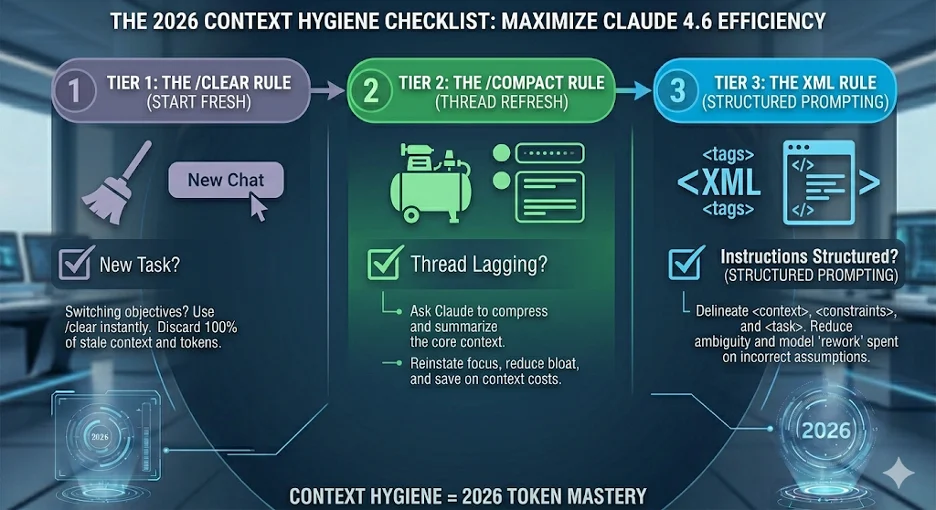
- The /Clear Rule: When switching tasks—even slightly—start a fresh session. Stale context is not just expensive; it’s a distraction. If you need to keep the history, rename the session and start fresh.
- The /Compact Rule: For long tasks, instruct Claude to summarize the current state and restart. This preserves the “mental model” while shedding thousands of unnecessary tokens. This instructs Claude to summarize the core findings, current state, and code samples, and then restart the session with only that summary.
4. Structural Efficiency: Why Claude Loves XML
In 2026, formatting is about Token Density. While JSON is common, XML tags are the native language of Claude’s reasoning engine. XML tags like <context>, <task>, and <constraints> clearly separate instructions from data, preventing “Instruction Drift” and reducing the need for costly follow-up corrections.
- Token Optimization: XML allows Claude to “chunk” information more effectively. It identifies the start and end of blocks with fewer tokens than verbose prose.
- The “Ultra-Compressed” Mode: High-level users are now using a community-developed “shorthand” inside XML tags. Instead of saying “Please ensure you follow the coding standards listed below,” they use
<rules:standard_v2 />.
Treat your prompt like a well-structured XML document. It’s the difference between giving a contractor a messy pile of papers and a structured blueprint.
The Token Optimization Checklist
Your 2026 Protocol for Efficient AI Usage
Architectural Foundations
- Apply Model Tiering: Use Haiku for routing/formatting, Sonnet for logic, and Opus only for strategy.
- Utilize “Projects” or System Prompts: Store persistent context (brand voice, code standards) in a Project system prompt rather than re-pasting it every time.
- Implement Zero-Copy Federation: If using the API, mount data via MCP (Model Context Protocol) rather than uploading massive files.
Prompt Engineering & Structure
- Front-Load Stable Content: Place your most static information (Instructions, Background) at the very top of the prompt to trigger caching.
- Use XML Delimiters: Wrap your inputs in tags like <input> and <instructions> to reduce ambiguity and prevent re-work.
- Surgical Edits Only: Don’t paste an entire 500-line script to fix one bug. Paste only the relevant function.
- Outline First: Request a “skeleton” or outline for long documents. Approve the structure before Claude spends tokens on a full 2,000-word draft.
Session Management
- Edit Instead of Following Up: If Claude misses the mark, click the Edit icon on your original prompt. This replaces the old context instead of adding a new “correction” turn.
- The 15-Message Reset: Start a fresh chat every 15–20 turns. Long threads exponentially increase the cost of every new message.
- Use /Compact Regularly: Periodically ask Claude to “Summarize our current progress and key decisions into a single block, then start a new session.”
- Define Output Constraints: Explicitly state “Respond in under 200 words” or “Use bullet points” to prevent “token sprawl” in responses.
About the author
Eshaan Jain serves as a Senior Product Manager at Mphasis, focusing on Revenue Operations and AI and CPQ transformations across Enterprise, Government, and Education sectors. He designs and implements Quote-to-Contract (Q2C) and Contract Lifecycle Management (CLM) platforms. Eshaan earned his MS in Computer Science from the prestigious University of Southern California and has over 13 years of experience with enterprise systems at organizations like Amazon, PwC, and Accenture. He has published research on mobile cloud computing architectures and Artificial Intelligence in leading journals such as IEEE and Elsevier and holds multiple Salesforce certifications. For more insights on AI in the quote-to-cash cycle, product management and Salesforce related content connect with him on LinkedIn







thanks for info.