

OmniStudio DataRaptors typically supply data to OmniScripts, Integration Procedures, and Cards, and write updates from OmniScripts, Integration Procedures, and Cards to Salesforce. In this post we will talk about what is OmniStudio DataRaptor and Type of DataRaptor.
What is OmniStudio DataRaptor?
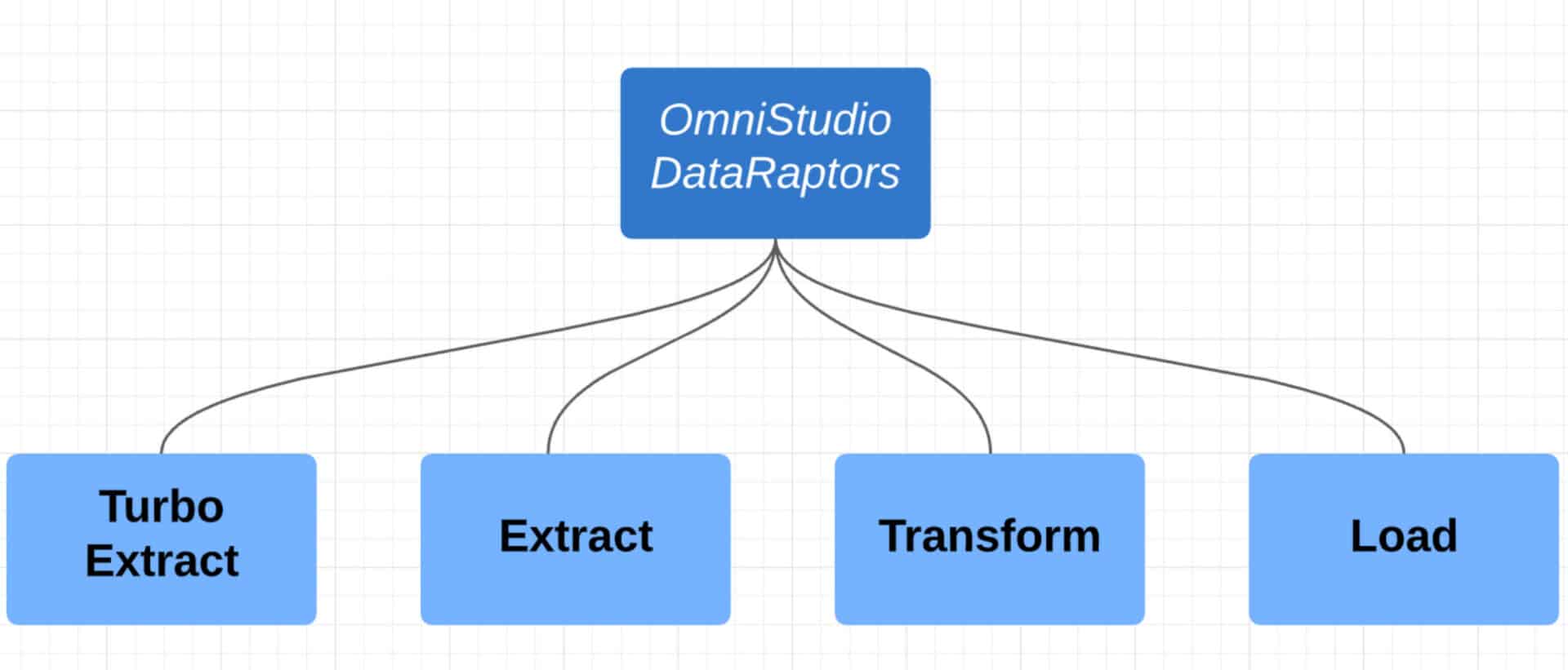
Think of it this way: for every digital customer interaction or business process, your system needs to extract data to display it. When the user changes that data or enters new data, it must be saved too. That’s where OmniStudio DataRaptors come in. A DataRaptor is a mapping tool that enables you to read, transform, and write Salesforce data. There are four types of DataRaptor: Turbo Extract, Extract, Transform, and Load.
DataRaptors Code Capabilities
Here are some code capabilities of DataRaptor (DR) in Salesforce:
- ETL For Salesforce : DataRaptor Mapping tool enable read, write and transform JSON and XML inputs. It also helped in perform intermediate data transformation without reading from or writing to Salesforce.
- Declarative no code/ Low Code : DataRaptor is a declarative tool and no code is required to get data from Salesforce.
- Substitute for Apex: Although apex classes can read write and transform data they can take longer to create and are harder to maintain then dataRaptors. Therefore, use dataRaptor as Vlocity best practice.
- Handle custom data Formulas : DataRaptor Extract and Load can handle custom data formats. It can access external object and custom metadata as well as sObject.
Type of OmniStudio DataRaptors
Let understand the different type of OmniStudio DataRaptors.
- Turbo Extract: Read data from a single Salesforce object type, with support for fields from related objects. Then select the fields to include. Formulas and complex field mappings aren’t supported.
- Extract: Read data from Salesforce objects and output JSON or XML with complex field mappings. Formulas are supported. We can data from one or more Objects.
- Transform: Perform intermediate data transformations without reading from or writing to Salesforce. Formulas are supported.
- Load: Update Salesforce data from JSON or XML input. Formulas are supported.
Note – Dataraptor can access external objects and custom metadata
1. DataRaptor Turbo Extract
A DataRaptor Turbo Extract retrieves data from a single Salesforce object type, with support for fields from related objects. You can filter the data and select the fields to return. DataRaptor Turbo Extract doesn’t support formulas. There’s no Output tab, so you can’t use mappings to structure the output. Custom JSON, default values, and translations aren’t supported. But it
- Simpler configuration
- Better performance at runtime
2. DataRaptor Extract
DataRaptor Extracts read Salesforce data and return results in JSON, XML, or custom formats. You can filter the data and select the fields to return. Formulas, default values, and translations are supported. Extracts typically provide OmniScripts, Integration Procedures, and Cards with the data they require.
3. DataRaptor Transform
DataRaptor Transforms let you perform intermediate data transformations without reading from or writing to Salesforce. Formulas are supported.
- Convert JSON input to XML output, and vice versa
- Restructure input data and rename fields
- Substitute values in fields (all DataRaptors can substitute values)
- Convert data to PDF, DocuSign, or Document Template format
4. DataRaptor Load
DataRaptor Loads accept data in JSON, XML, or custom input formats and write the data to Salesforce objects. Formulas and attributes are supported. For example, when a user running a case-handling OmniScript finishes entering data and clicks Save, the script calls a DataRaptor Load to record the data entered.
DataRaptor Designer
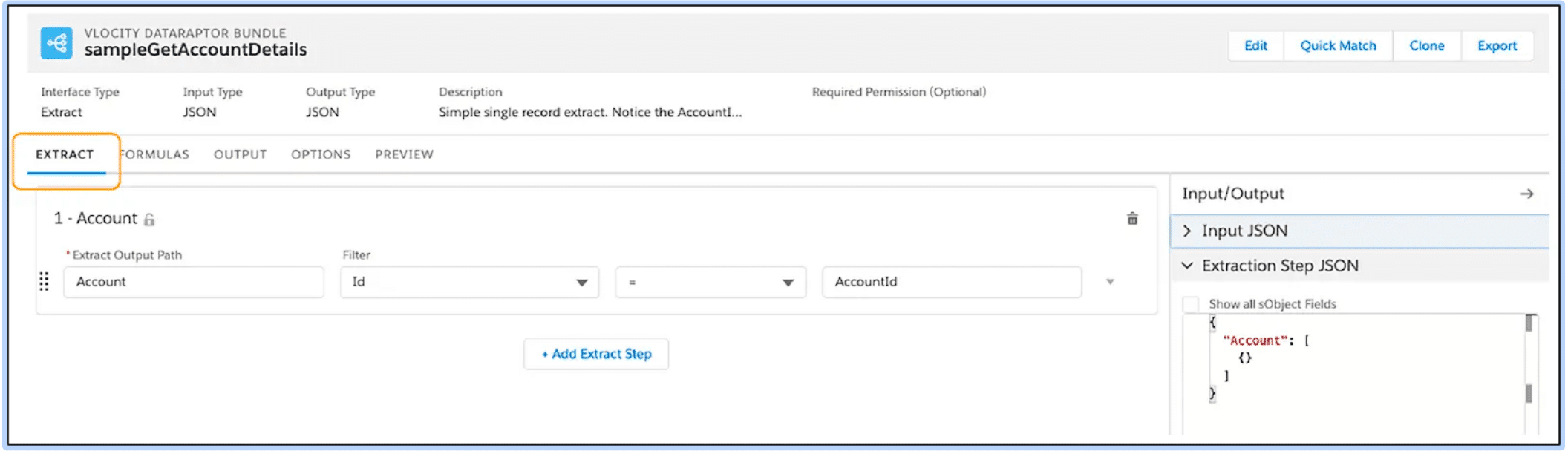
Extract Tab – Specify the Salesforce objects you want the DataRaptor to query and the filters that determine the data to be returned from the object
Formula Tab – Define a formula, you map its output to the output JSON (for extracts and transforms) or Salesforce object field (for loads).

Dataraptor Functions : Change the data you are working with in more complex ways than with mapping inputs and outputs, use functions
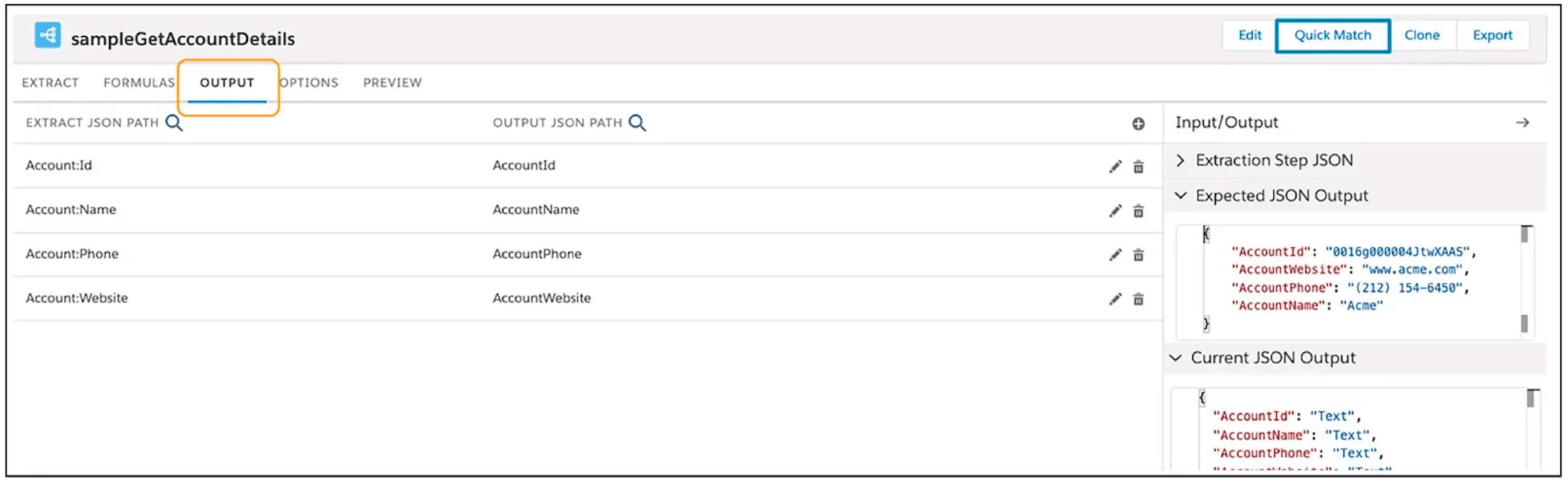
Output Tab – map data from the extract step JSON to the output JSON
Options Tab – Set advanced options for execution. you set advanced options such as whether to check the user’s access permissions for the fields before executing the DataRaptor. Set the Platform Cache Type to Session Cache for data related to users and their login sessions, or Org Cache for all other types of data. The Time to Live in Minutes setting determines how long the data remains in the cache.
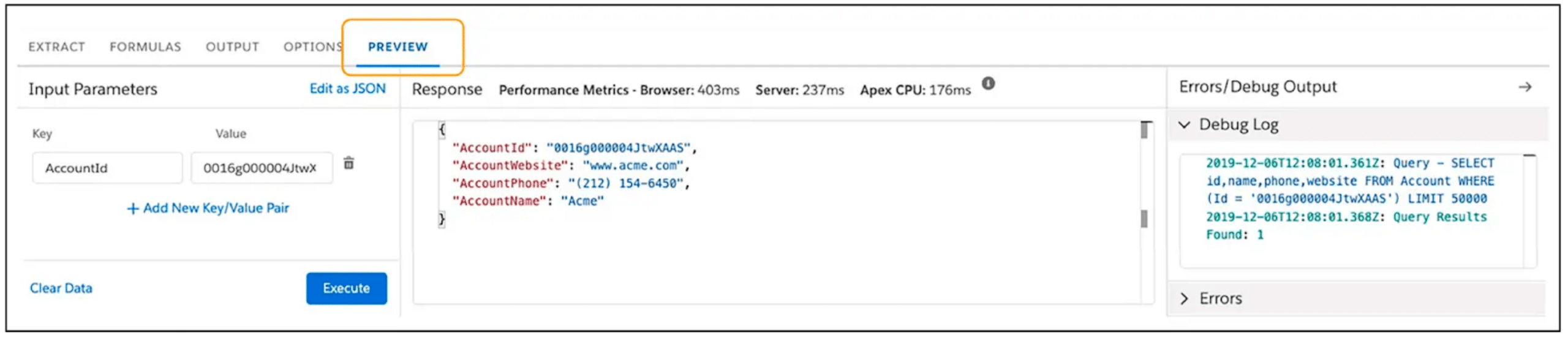
Preview Tab – Test the output of the DataRaptor.
Top Common Mistakes of DataRaptors
Here are some common mistake for Data Raptors.
- VlocityMetadata Platform Cache is not set
- Teams are adding objects to the DataRaptors to get data that could be accomplished by using relationship queries
- Teams are trying to create “Uber” DataRaptors to cover as many of their data needs as possible. (as high as 12 Objects)
- DataRaptor receives more data than needed
- DataRaptor uses many formulas (as high as 30)
OmniStudio DataRaptors Best Practices
Follow below OmniStudio DataRaptors best practices.
| Allocate space to Vlocity Metadata Platform Cache | Allocate space to Vlocity Metadata to cache DataRaptor Metadata. Allocate space only to Org Cache. You can allocate 5 MB or what is needed in your context. |
| Create targeted DataRaptors and limit the number of Objects to 3 where possible | Create targeted DataRaptors that only extract or load the data needed for one operation. Try to keep the number of objects to 3 or less |
| Use Relationship Query to reduce the number of Extract Objects | Use relationship notation (queries) whenever possible to pull data from other SObjects. |
| Trim the data sent to and received from DataRaptor | Send only the necessary input and return only the outputs you need. |
| Reduce where possible DataRaptor Formula | DataRaptor works in series, limit where possible the number of formulas for better performance |
| Use Turbo Extract, more performant where possible | When you have 1 Object to extract and no formula, Use Turbo |
| Use DataRaptor Data Cache (Session or Org)where possible | Use caching to store frequently accessed, infrequently updated data |
| Ensure that all filters and sorts have supporting indexes | Ensure that all filtering and sorting (ORDER BY) operations are on indexed fields. The Id and Name fields are always indexed. |
| Use OOTB functionality where possible before creating a custom Formula | Before creating a new formula, check the solution with: OOTB formula Output Type OOTB config (Map Values) |
| Server processing time must be under 5 sec. | For synchronous Transaction, to avoid hitting Salesforce Governor Limits for Long Running Transaction, processing time must be under 5 sec. |
Recording
DataRaptor Naming Conventions
- DataRaptor Names Must be unique within the org and there should be No spaces
- Use camelCase – prefix, Verb, Object and Detail
- Use an action verb and descriptive nouns
- Use abbreviations
- Example : prefixVerbObjectDetail and teamGetAcctCases
Summary
DataRaptor is a declarative extract-transform & load tool that runs natively on the Salesforce platform.






Hi Amit,
I have a requirement, but unable to achieve using DataRaptors.
I should fetch the accounts and related contact in the below format from dataraptor.
Account[
{Name: ACC1,
contact:[{
name : con 1A;
name : con 1B;
}]
}
{
Name : Acc2,
Contact:[{
name: con 2A;
name: con 2B;
}]
}
]
Hi Amit,
I have a requirement, but unable to achieve using DataRaptors.
I should fetch the accounts and related contact in the below format from dataraptor.
Account[
{Name: ACC1,
contact:[{
name : con 1A;
name : con 1B;
}]
}
{
Name : Acc2,
Contact:[{
name: con 2A;
name: con 2B;
}]
}
]
Please let me know if you have any idea about this.