

GDPR fines for data breaches exceeded €2.1 billion in 2023, with Meta’s record €1.2 billion penalty from Ireland’s Data Protection Commission highlighting the stakes—and using production data in non-production Salesforce environments remains a critical compliance risk. Yet most development teams still struggle with mock data generation—breaking validation rules, exposing PII, and creating unrealistic test scenarios that collapse in production.
The challenge: Traditional mock data generators like Mockaroo create generic datasets that fail in Salesforce’s complex ecosystem. TestDataFactory patterns work for unit tests but collapse at system scale. Manual seeding is time-consuming, error-prone, and impossible to reproduce across environments.

Good vs Bad Quality Mock Data
The Hidden Complexity of Salesforce Mock Data
Creating realistic test data for Salesforce isn’t just about filling fields with random values. The platform’s sophisticated architecture introduces challenges that generic data generators simply can’t handle.
What Makes Salesforce Mock Data Different?
Multi-object relationships: Salesforce’s strength lies in its relational data model. Accounts connect to Contacts, Opportunities link to Products, and Cases reference Assets. Generic tools like Mockaroo generate isolated records without understanding these dependencies. When your validation rules expect a Contact to have a valid Account, or your flows require specific field combinations, naive data generation fails spectacularly.
Validation rule complexity: Real Salesforce orgs contain dozens of validation rules that enforce business logic. A simple Account record might require specific combinations of Industry, Type, and custom fields. Mock data that ignores these rules creates test scenarios that never occur in production, leading to false confidence in your code.
Dependent picklist handling: Standard tools struggle with Salesforce’s dependent picklists where State values depend on Country selection. This seemingly simple relationship becomes a nightmare when generating thousands of records that need realistic geographic combinations.
Record type considerations: Different record types enable different fields and picklist values. Mock data generators that ignore record types create invalid field combinations that would never pass Salesforce’s built-in validation.
Current Approaches and Their Limitations
TestDataFactory patterns: The Salesforce community widely adopts TestDataFactory classes for unit test data. These work excellently for focused unit tests with 5-10 records, but they collapse when you need hundreds or thousands of records for integration testing, performance validation, or sandbox seeding. The manual coding overhead becomes unsustainable, and maintaining relationships across multiple objects requires complex dependency management.
Mockaroo and generic tools: External data generators excel at creating realistic-looking individual fields—names, emails, addresses. However, they’re completely unaware of Salesforce’s metadata, validation rules, and object relationships. A recent Reddit discussion highlighted this frustration: developers need “dummy salesforce data” but find generic tools create records that fail basic Salesforce validation.
Manual seeding approaches: Many teams resort to exporting production data, manually scrubbing PII, and importing sanitized datasets. This approach is time-consuming, error-prone, and creates compliance risks. Worse, it’s impossible to reproduce consistently across environments or scale for different testing scenarios.
CSV imports and data loader: While functional, this approach requires significant manual effort to maintain referential integrity. Creating lookup relationships manually across CSV files becomes exponentially complex as object count increases.
Compliance and Security Imperatives
PII/PHI protection requirements: Regulations like GDPR, CCPA, and HIPAA mandate strict controls over personally identifiable information. Using production data in non-production environments—even “anonymized”—creates compliance risks. Salesforce Data Mask provides official guidance on this challenge. True synthetic data generation eliminates these concerns by creating realistic but entirely artificial datasets.
Audit trail and reproducibility: Compliance frameworks require documented, reproducible processes. Manual data creation fails audit requirements because it’s impossible to demonstrate consistent, repeatable procedures. Automated synthetic data generation with versioned templates provides the audit trail compliance teams demand.
Data residency and sovereignty: Global organizations must consider where test data is stored and processed. Synthetic data generation allows teams to create compliant datasets in any geography without cross-border data transfer concerns.
Synthetic vs. masked data trade-offs: Data masking transforms real data by replacing sensitive fields with realistic alternatives. While effective, it still requires handling actual PII during the masking process. Salesforce’s official Data Mask documentation outlines these constraints. Synthetic data generation bypasses this entirely by creating artificial datasets that maintain statistical properties without ever touching real customer information.
The bottom line: Salesforce’s complexity demands purpose-built solutions that understand the platform’s metadata, validation rules, and relationship requirements while maintaining strict compliance standards.
See also: Apex Test Class Best Practices for foundational testing strategies and Salesforce Best Practices Guide for sandbox testing approaches.
How Does Smock-it Solve Salesforce Mock Data Challenges?
Smock-it v3.0.3 addresses the fundamental challenges of Salesforce mock data generation through a purpose-built CLI plugin that understands the platform’s complexity from the ground up. As organizations adopt modern Salesforce DevOps practices, the need for automated, compliant test data generation becomes critical.
What is Smock-it?
CLI-based Salesforce integration: Smock-it operates as a Salesforce CLI plugin (sf plugins install smock-it), integrating seamlessly with existing development workflows. Unlike external tools that require data export/import cycles, Smock-it connects directly to your Salesforce orgs through the CLI’s authentication system.
Headless operation support: Designed for modern DevOps workflows, Smock-it operates entirely through command-line interfaces. No GUI dependencies mean it runs reliably in CI/CD pipelines, Docker containers, and automated testing environments.
Natural language processing: The new Promptify feature (sf smockit promptify) allows teams to describe their data requirements in natural language. For ex Generate 100 Accounts with Technology Industry generates a working template without manual JSON configuration.
No passwords asked: Works on top of previously authorised orgs via “SF” CLI, i.e.
sf org login web –alias sandbox-partial
Smock-it commands use the same org alias only, i.e.
sf smockit data generate -t [Template-Name.json] -a sandbox-partial
Key Differentiators
JSON template configuration: Smock-it uses structured JSON templates that define data generation rules:
{
"namespaceToExclude": [],
"outputFormat": ["csv", "json"],
"count": 1,
"sObjects": [
{"account": {}},
{"contact": {}},
{
"lead": {
"count": 5,
"fieldsToExclude": ["fax", "website"],
"fieldsToConsider": {
"email": ["smockit@gmail.com"],
"phone": ["9090909090","6788899990"]
},
"pickLeftFields": true
}
}
]
}
Dependent picklist intelligence:
- Unlike generic tools, Smock-it reads your org’s metadata to understand dependent picklist relationships.
- Smock-it handles Salesforce dependent picklists through a special naming convention. Fields prefixed with dp- (e.g., dp-country__c, dp-state__c) in template above, indicate dependent relationships where child picklist values depend on parent selections.
- In the example above, dp-state__c: [“California”] will only accept valid state values for dp-country__c: [“USA”], maintaining hierarchical field dependencies as configured in your Salesforce org.
Schema-aware data generation: Smock-it reads your org’s metadata to understand field types, picklist values, and required fields, generating data that aligns with your Salesforce schema. The template validation command helps identify configuration issues before data generation, reducing the risk of validation failures.
Multiple output formats: Generate data as CSV files for bulk import, JSON for API operations, or direct insert (DI) for immediate org population. This flexibility supports different testing and deployment scenarios.
Flexible field control: Smock-it provides granular control over field generation through fieldsToConsider and fieldsToExclude parameters, allowing you to specify exactly which fields to populate or skip. The pickLeftFields setting determines whether remaining fields are auto-generated or left empty, giving you precise control over data structure.
Namespace handling: Smock-it can exclude specific namespaces from data generation, crucial for managed package environments where you need to focus on core platform objects.
Scalability and performance: Designed to handle large datasets efficiently, Smock-it addresses the scalability issues and complex data structure challenges that plague manual approaches, generating thousands of related records while maintaining referential integrity.
How Do You Get Started with Smock-it?
This step-by-step guide walks through setting up Smock-it and generating your first synthetic dataset, using real CLI commands and practical examples.
Setup and Prerequisites
- Install prerequisites: SF CLI, Node.js, Active Salesforce org with appropriate permissions.
- Install Smock-it plugin: sf plugins install smock-it
- Authenticate target SF org(as needed): sf org login web –alias myorg
Creating Your First Mock Data Template
sf smockit template init
This command launches an interactive questionnaire that guides you through template configuration. You’ll specify:
- Objects to generate (Account, Contact, Opportunity, etc.)
- Record counts for each object
- Fields to include/exclude
- Output formats (CSV, JSON, or direct insert)
- Relationship handling preferences

Generation and Deployment Workflow
Validate your template:
sf smockit template validate -t myTemplate.json -a myorg
This command checks your template against your org’s metadata, identifying potential issues before generation.
Generate realistic mock data:
sf smockit data generate -t myTemplate.json -a myorg
Smock-it creates three output files in the data_gen/output/ directory:
- MyTemplate_DI_Output.json – Direct insert format
- MyTemplate_CSV_Output.csv – CSV for bulk import
- MyTemplate_JSON_Output.json – JSON for API operations
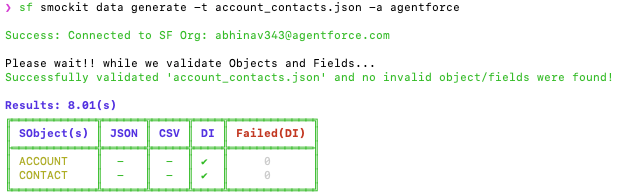
The above screenshot shows DI (Direct Insert), where the org is populated with records in < 10 seconds.
Upload to additional orgs (if needed):
sf smockit data upload -u MyTemplate_JSON_Output.json -a secondorg -s Account
How Do You Integrate Smock-it with CI/CD Pipelines?
Modern Salesforce development demands automated testing with realistic data. Smock-it’s headless operation makes it ideal for CI/CD integration, providing consistent test data across pipeline stages. Whether you’re building your own CI/CD pipeline or using enterprise solutions, Smock-it fits seamlessly into your workflow.
GitHub Actions Integration Pattern
- Check this step-by-step guide to setting up Smock-it in Github actions.
- Example Github YML file: https://github.com/concretios/smock-it/blob/main/.github/workflows/smock-it.yml
Environment-specific data generation: Use matrix strategies for multiple environments:
strategy:
matrix:
environment: [dev, staging, uat]
include:
- environment: dev
template: devTemplate.json
record-count: 100
- environment: staging
template: stagingTemplate.json
record-count: 500
- environment: uat
template: uatTemplate.json
record-count: 1000
steps:
- name: Generate Environment-Specific Data
run: |
sf smockit template upsert -t ${{ matrix.template }} -c ${{ matrix.record-count }}
sf smockit data generate -t ${{ matrix.template }} -a ${{ matrix.environment }}org
💡 Pipeline Tip: Version control templates alongside code; use sf smockit template validate in pre-commit hooks
Standard Salesforce DX workflow:
- name: Deploy Metadata
run: sf project deploy start --target-org testorg
- name: Generate Test Data
run: sf smockit data generate -t postDeployTemplate.json -a testorg
- name: Run Integration Tests
run: sf apex run test --test-level RunSpecifiedTests --tests IntegrationTestClass --target-org testorg
See also: CI/CD Pipeline using GitLab for Salesforce for alternative platform implementation patterns and Branching Strategies for Salesforce for version control best practices.
What Are the Best Practices for Sandbox Seeding with Smock-it?
Sandbox environments serve multiple purposes beyond development testing. Smock-it provides consistent, repeatable seeding strategies for each use case while maintaining compliance and governance standards. For enterprise implementations, review sandbox design strategies to align your seeding approach with organizational architecture.
Use Case Scenarios
UAT environment preparation: User Acceptance Testing requires realistic data volumes that mirror production patterns without exposing sensitive information. Create UAT-specific templates that generate:
- Representative account hierarchies with parent-child relationships
- Contact records with realistic role distributions
- Opportunity pipelines reflecting actual sales cycles
- Case histories demonstrating support workflows
# UAT seeding with production-like volumes
sf smockit template init --default
sf smockit template upsert -t uatTemplate.json -s Account -c 500
sf smockit template upsert -t uatTemplate.json -s Contact -c 1500
sf smockit template upsert -t uatTemplate.json -s Opportunity -c 750
sf smockit data generate -t uatTemplate.json -a uat-sandbox
💡 Other seeding scenarios: Apply the same pattern for training/demo orgs (clean, scenario-based data) and performance testing (10,000+ records with maintained referential integrity). Adjust template record counts and object selection based on your specific testing requirements.
Seeding templates and versioning: Maintain template libraries organized by purpose and environment:
./data_gen/templates/uat.json - User acceptance testing template
./data_gen/templates/training.json - Training and demo template
./data_gen/templates/performance.json - Load testing template
./data_gen/templates/integration.json - API and integration testing templateVersion control templates alongside your metadata to ensure consistency across deployments.
💡 Create environment-specific seeding playbooks that combine Smock-it templates with post-seeding configuration steps, ensuring consistent, compliant sandbox preparation across your organization.
See also: Development and Deployment Process for comprehensive release management frameworks that incorporate test data strategies.
Which Mock Data Tool Should You Choose?
Choosing the right mock data tool depends on your specific requirements, technical constraints, and team capabilities. Here’s how Smock-it compares to established alternatives in the context of modern DevOps workflows.
Quick decision guide:
| Use Case | Best Tool | Why |
|---|---|---|
| Fast setup + CI/CD | Smock-it | Interactive init, JSON templates, Promptify NLP |
| Complex data recipes | Snowfakery | YAML/Jinja DSL, correlated patterns, CumulusCI |
| Org-to-org migration | SFDMU | Preserves relationships, production-scale |
When to Use Smock-it
Best for:
- Teams new to synthetic data (low learning curve)
- CI/CD pipeline automation (headless operation)
- Compliance-first environments (no PII handling)
- Multi-environment seeding (dev → staging → UAT)
Requirements: Salesforce CLI + Node.js v18+
When to Use Snowfakery
Best for:
- Complex business logic requiring custom recipes
- Teams using CumulusCI workflows
- Correlated data patterns (industry/region/product mix)
- Advanced conditional data generation
Requirements: CumulusCI + Python + YAML/Jinja templating skills
When to Use SFDMU
Best for:
- Production data migration between orgs
- Large-scale operations (millions of records)
- Preserving existing relationships and data integrity
- Complex SOQL-based data extraction
Requirements: Salesforce CLI + Advanced SOQL skills + Manual data masking for compliance
The bottom line: Smock-it excels in scenarios requiring quick setup, natural language configuration, and compliance-first synthetic data generation. Snowfakery suits teams needing complex customization within CumulusCI workflows. SFDMU remains the gold standard for data migration and large-scale data operations.
Looking Ahead: Smock-it for Apex Library
The Smock-it for Apex Library will bridge CLI-based data generation with programmatic Apex testing patterns, bringing template-based synthetic data directly into test classes.
Expected capabilities:
- Native Apex integration with familiar Smock-it template syntax
- Reusable test fixtures across methods
- Fluent API for complex object hierarchies
- Natural language descriptions converted to Apex code
The library complements existing TestDataFactory patterns rather than replacing them, with development driven by community feedback. Stay tuned to the Smock-it GitHub repository for early access opportunities.
Frequently Asked Questions
How does Smock-it handle complex object relationships?
Smock-it reads your org’s metadata to understand object relationships automatically. When you define parent objects (like Account) in your template, Smock-it creates child records (like Contact) with proper lookup relationships. For master-detail relationships, it ensures referential integrity by creating parent records first. Complex scenarios involving multiple relationship levels are handled through template ordering and dependency resolution.
What are the performance implications for large datasets?
Smock-it is optimized for datasets ranging from hundreds to thousands of records. For very large datasets (10,000+ records), consider batch processing using multiple smaller templates or parallel generation. The tool includes built-in performance monitoring and will provide warnings for templates that may exceed reasonable generation times. Direct insert (DI) format typically performs better than CSV import for large datasets.
Can Smock-it integrate with existing testing frameworks?
Yes, Smock-it integrates seamlessly with standard Salesforce testing approaches. Use it alongside existing TestDataFactory classes for hybrid scenarios—generate bulk data with Smock-it and create specific test scenarios with traditional Apex patterns. The upcoming Smock-it for Apex Library will provide even tighter integration with programmatic testing frameworks.
Does Smock-it work with custom objects and fields?
Absolutely. Smock-it reads your org’s complete metadata, including custom objects, custom fields, and custom relationships. It respects field-level security, validation rules, and record type configurations for custom objects just as it does for standard objects. Custom namespace handling ensures compatibility with managed packages and custom development.
Conclusion & Action Plan
Salesforce mock data generation doesn’t have to be a bottleneck in your development process. Smock-it provides a comprehensive solution that addresses the platform’s unique challenges while maintaining compliance and supporting modern DevOps workflows.
Implementation roadmap:
- Start simple: Install Smock-it and generate basic Account/Contact template.
- Expand gradually: Add custom objects and complex relationships as you understand your org’s patterns
- Integrate with CI/CD: Implement automated data generation in your deployment pipelines
- Establish governance: Create template libraries and validation processes for team consistency
Continue learning with Apex Hours:
- Test Data Factory in Salesforce – Complementary testing patterns
- Mocking Apex Tests – Advanced testing techniques
- Apex Test Class Best Practices – Testing fundamentals
- Salesforce DevOps Guide – Complete DevOps implementation strategies
- CI/CD Pipeline using GitLab – Pipeline automation alternatives
- Sandbox Design Strategies – Enterprise sandbox management
- SOQL Performance Tuning – Query optimization for large datasets
- Salesforce Performance Best Practices – System optimization strategies
Want to stay updated on Salesforce testing and DevOps best practices? Subscribe to the Apex Hours newsletter for weekly insights, tutorials, and community events.
Additional Resources & Tools
Smock-it Official Resources:
- Smock-it GitHub Repository – Installation, documentation, and examples
- Template Init Questionnaire – Detailed template creation guide
- Promptify Guide – Natural language data generation
- GitHub Actions Integration Guide – CI/CD workflow patterns
Official Salesforce Documentation:
- Salesforce Data Mask Platform – Enterprise data protection
- Data Mask Documentation – Official compliance guidance
- Sandbox Seeding Overview – Salesforce’s sandbox seeding capabilities






