

In this session/post we will talk about Large Data Volumes (LDV) & Data Management. We will also cover how to make Strategies for dealing with LDV scenarios in Salesforce, common data and sharing consideration, Data load Strategy in Salesforce. This session is highly recommend for those who are studying for their Data Architecture & Management Designer certification exam and those on the #journey2cta.
Large Data Volumes (LDV) in Salesforce
Large Data Volumes (LDV) in Salesforce is an imprecise, elastic term. These large data volumes(LDV) can lead to sluggish performance, including slower queries, slower search and list views, and slower sandbox refreshing.
Why is LDV important?

Under the hood
Salesforce Platform Structure
- Metadata Table: describe custom objects and fields
- Data Table: containing the physical records in your org
- Virtual Database: A virtualization layer which combines the data and metadata to display the underlying records to the User
- Platform takes the SOQL entered by the user which is converted to native SQL under the hood to perform necessary table joins and fetch the required information.
How does Search Work?
- Record takes 15 minutes to be indexed after creation.
- Salesforce searches the Index to find records.
- Found rows are narrowed down using security predicates to form Result Set.
- Once Result-Set reaches a certain size, additional records are discarded.
- ResultSet is used to query the main database to fetch records.
Force.com Query Optimizer
System responsible for generating optimal query execution paths in Salesforce, and performing table joins to fetch the underlying data.
Learn How Salesforce Query Optimizer works for LDV.
Skinny Tables
What is a skinny table?
Condensed table combining a shortlist of standard and custom fields for faster DB record fetches.
Key Facts
- Salesforce stores standard and custom field data in separate DB Tables
- Skinny table combines standard and custom fields together
- Data fetch speed is improved with more rows per fetch.
- Do not contain soft-deleted records
- Best for > 1M records
- Immediately updated when master tables are updated
- Usable on standard and custom objects
- Created by Salesforce Support
Learn more about Skinny Table in Salesforce.
Indexing Principles
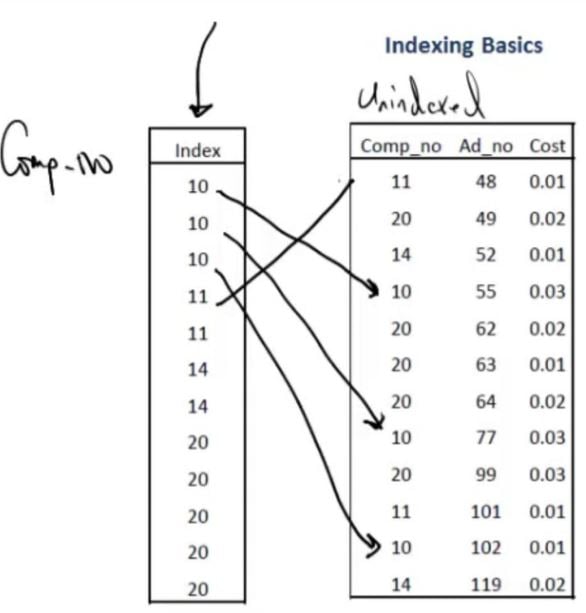
What is an index?
- Sorted column, or combination of columns which uniquely identify rows of data.
- Index contains sorted column and pointers to the rows of data.
Example
- Created index on Comp_no field.
- [SELECT * FROM Table WHERE Comp_no > 14].
- Query uses the Sorted Comp_no (Index) column to quickly identify data rows.
- Query does not need to do full table scan to fetch rows.
Standard vs Custom Index
Standard Index
Salesforce creates standard index on the following fields
- RecordTypeId
- Division
- CreatedDate
- LastModifiedDate
- Name
- Foreign Key Relationships [Master-Detail and Lookup]
- Salesforce Record Id
- External Id and Unique fields
Custom Index
Created an index for custom fields frequently used in reports or custom queries.
- Can be created on formula fields
- Cannot be created for:
- multi-picklist
- currency field
- long text field
- binary fields
- Cannot be created for columns with NULL values
Two Column Index: Useful when one column is to select the records to display, and the other column is to sort
Indexing Pointers
How does Salesforce Query Optimizer use Indexes?
- Force.com Query Optimizer determines which index to use.
- Standard Indexed Fields: If query filter matches < 30% of first million records then use standard index.
- Custom Index Fields: Used if filter matches < 10% of total records, up to max 333,333 records.
- Salesforce determines % of records to be returned when evaluating index use.
- A query is selective if index can be used – “Please write selective queries”.
- Performance of SOQL query improves when two or more filters in the where clause meet the above conditions.
- Salesforce checks for frequently run queries and creates an index if it will improve the query performance.
- Force.com query optimizer makes decisions to use table scan, indexing etc, and what order to perform joins in to best optimize the execution of the query
Check our old session recording to learn about How Salesforce Query Optimizer works for LDV.
Best Practices
How should we improve performance under Large Volumes?
- Aim to use indexed fields in the WHERE clause of SOQL queries
- Avoid using NULLS in queries as index cannot be used
- Only use fields present in skinny table
- Use query filters which can highlight < 10% of the data
- Avoid using wildcards in queries, such as % as this prevents use of an index
- Break complex query into simple singular queries to use indexes
- Select ONLY required fields in SELECT statement
Common Data Considerations
Lets talk about what are common data consideration :
Ownership Skew
When you have more than 10,000 records for a single object owned by a single owner.
Why does this cause problems?
- Share Table Calculations: When you move a user in the Role Hierarchy, sharing calculations need to take place on large volumes of data to grant and revoke access.
- Moving users around the hierarchy, causes the sharing rules to be re-calculated for both the user in the hierarchy, and any users above this user in the role hierarchy.
How can we avoid this?
- Data Migration: Work with client to divide records up across multiple real end-users
- Integration User: Avoid making integration user the record owner
- Leverage Lead and Case assignment rules
- If unavoidable: assign records to a user is an isolated role at the top of the Role Hierarchy
Parenting Skew
When you have more than 10,000 records for a single object underneath the same parent record
Why does this cause problems?
- Data Migration: Bulk API batch size is 10,000. Records in parallel batches linked to the same parent will force the parent to be updated potentially causing record locking.
- Implicit Sharing: Where access to a parent record is driven by access to children. If you lose access to child record, Salesforce must check every other child record to determine continued access to parent.
How can we avoid this?
- Avoid having > 10,000 records of a single object linked to the same parent record.
- When you have free-hanging contacts that need to be associated to accounts, distribute these across multiple accounts.
- Using a picklist field: when dealing with a small number of Lookup records, use a Picklist field instead
Sharing Considerations
Lets talk about sharing consideration for LDV. Please check our old session on Sharing Architecture.
Org Wide Defaults
What should I do
- Set OWDs to Public R/W and Public R/O where possible for non-confidential data
- Reduce the requirement for a share table.
- Use ‘Controlled by Parent’ to avoid additional share tables
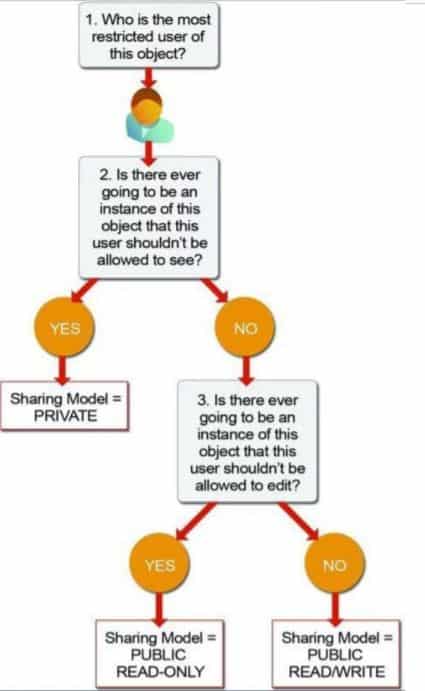
Sharing Calculation
Parallel Sharing Rule Re-calculation
- Sharing rules are processed synchronously when Role Hierarchy updates are made.
- Sharing rules can be processed asynchronously and split into multiple execution threads, so a single sharing rule calc can be executed on parallel threads.
- For long-running role calculations ask SFDC to enable parallel sharing rule re-calculation.
Deferred Sharing Rule Calculation
- Make Role Hierarchy updates, Sharing Rule changes and Group Membership changes up front.
- Share Table calculations across objects are deferred
- Re-enable Sharing Calculations once amendments are complete
- Contact SFDC to enable this functionality
- Test the process in a sandbox environment first and verify the results and timings.
- Negotiate a window with the customer and perform deferred sharing rule recalculation
Granular Locking
- When performing updates to roles and groups, the entire group membership table is locked for data integrity.
- Multiple updates to the roles/groups may cause locking when done concurrently.
- System employs additional logic to allow multiple updates to proceed simultaneously if there is no hierarchical or other relationship between the roles or groups involved
- Groups that are in separate hierarchies can be edited concurrently
Data Load Strategy

1. Configure Your Organization for Data Load.
- Enable parallel sharing rule recalculation and differed sharing rule recalculation
- Create Role Hierarchy and Load Users.
- setup OWD of object as public read/write- the one we want to load by setting the no sharing table needs to be maintained for the object, preventing sharing recalculation from needing to run during data loads.
- Disable workflows, Triggers, process builder, validation rules.
2. Prepare the Data Load
- Identify the data that you want to load in new org (eg data >1 year old, all active UK business unit accounts etc)
- Extract, Cleanse, Enrich, Transform the data and create record in the staging table.
- De-duplicate the data.
- Make sure data is clean, especially foreign key relationship
- Perform some initial batch testing in the Sandbox.
3. Execute the Data Load
- Load parent object before children. Extract parent keys for later loading
- User insert and update ahead of upsert- in upsert operation Salesforce internally validates the data based on Object’s Id or External Id. So upsert takes little bit longer time than insert or upsert.
- For updates: only send fields whose values have changed.
- group record by parents Id when using Bulk API to prevents lock failure in parallel batches.
- Use the BULK API when dealing whith > 50,000 records.
4. Configure your organization for production
- Defer sharing calculations whilst loads are in progress
- Change OWD for object from Public Read/Write back to public RO or Private after load is complete- Create Public Group / Queues. Create your sharing rules. Try these steps in sandbox first. Can ask SFDC to enable parallel sharing rules processing.
- Configure sharing rules- do these one at a time allowing one to complete before moving on. Or use deferred sharing, finish off sharing rule creation and let the sharing rule calculation happen on mass afterwards.
- Enable trigger, workflow and validation rules again.
- Create roll-up summary fields.
Off Platform Approaches
Please check our old session recording on Getting data out of Salesforce in near-realtime.
Archiving Data
How and Why should we archive data?
- To keep only current data accessible in Salesforce
- To improve performance of reports, dashboards and list views
- To improve SOQL query performance
- Compliance and regulatory purposes
- To maintain a data backup
- To ensure redundant data does not impact system reporting, analytics or general performance
1. Approach- Middleware Led

2. Approach- Using Heroku?

3. Approach – Big Objects
Check this post to learn about big object.

Approach 4 – Buy a tool
- Odaseva
- OwnBackup
LDV Recording
Further Learning
- How Lightning Platform Query Optimizer works for LDV
- Getting data out of Salesforce in near-realtime
- Data Architecture And Management Designer – Tips
- Building Scalable Solutions on Salesforce
Please let us know in comment if you like this session.






This session is very helpful, thanks Apexhours
Thanks to keep us motivated.
Small note, LastModifiedDate is not indexed by default, but SystemModstamp is.
Thanks for correction. I will update the same
Issues Found
Table of Contents Scrolling Issue
Page: https://www.apexhours.com/large-data-volumes-ldv-in-salesforce/
Issue: When scrolling down the page, the Table of Contents overlaps with or scrolls onto the header. It should remain positioned correctly and not cover the header while scrolling.
Code Syntax Error
Page: https://www.apexhours.com/batch-apex-in-salesforce/
Location: Search for:
global void execute(Database.BatchableContext BC, List). The code is incorrect as displayed.
Current:
global void execute(Database.BatchableContext BC, List<SObject)
Correct:
global void execute(Database.BatchableContext BC, List scope) {}
At a minimum, the missing > should be added after List.