

Hey there #Trailblazers, as promised in our last Heroku Series blog posts we are back again with something interesting to cover in this blog, so let’s get started!! In this blog we will be discussing a few architectural patterns how enterprises are leveraging Heroku for multi-org strategy to create a single source of truth, data archival for keeping the Salesforce platform performant. Lets learn about how to Leveraging Heroku to extend Salesforce Implementations and Beyond.
We all are aware of what Heroku is : The powerful and fully managed polyglot platform enabling developers to focus more on the application logic/app layer rather than spending time in maintaining the Infrastructure layer. (Check out the previous blog posts for an Introduction about heroku and more).
Leveraging Heroku for Multi-org strategy use case
With a rapidly growing need of delivering the best customer experiences and increasing ROI, large enterprises often end up leveraging multiple instances of the #1 CRM Platform “Salesforce”. It might vary based on geography barriers, multiple teams managing the sales lifecycle from different locations of the world. Different teams so different strategies and a different way of doing things, as a result of these above reasons often companies end up leveraging multiple salesforce orgs
Managing multiple org’s is not easy, also comes a question about Data quality. Is the customer sure they are not ending up creating duplicate records? How about the Reporting? If the customer wants to have a complete 360 view/reporting of their entire sales lifecycle irrespective of the enterprise locations how can they achieve it? How can they avoid duplicates and maintain data quality? Too much data in orgs means a slow and less performant system.
This is where Heroku comes to the rescue!!
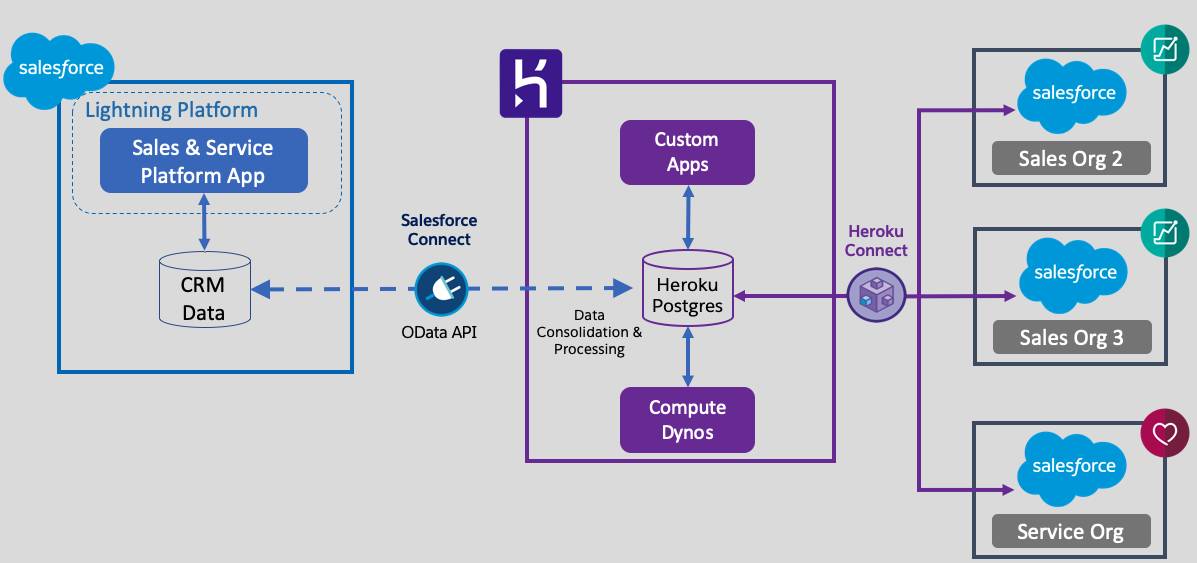
In the above architecture, the cross org/multi org problem is solved by leveraging Heroku connect. The data is replicated and synchronized from multiple Salesforce orgs in the Postgres Database of the Heroku Platform. Now, as the entire data from multiple orgs is stored in the Postgres DB, it can be simply queried using SQL and can be used in the Custom Apps hosted over the heroku platform. Thus enabling the enterprise to have a 360 view of their entire data over a custom app.
But how about reporting?? If the customer wants to run reports and visualize the entire data from multiple Salesforce orgs natively in one of the main Salesforce Org!! How can this be achieved?
For this purpose, Salesforce connect comes into the picture. Salesforce connect leverages OData adapters in order to access external data natively within Salesforce using External Objects. External Data is not stored in the Salesforce org but accessed in real time thus keeping the platform performant.
Salesforce Connect maps Salesforce external objects to data tables in external systems. Instead of copying the data into your org, Salesforce Connect accesses the data on demand and in real time. The data is never stale, and thus you access only what you need.
Once the data is accessed from the Heroku Postgres DB into the external objects natively in Salesforce, the “Enable Reports” permission must be enabled on the external object in order to run reports for the external data. After enabling the permissions, users will be able to run reports in varied formats for visualizing data natively in the main Salesforce org. Thus allowing the enterprise to analyse entire data for their efficiency and ROI, check for duplicate records, and have a Single/360 view of their entire data from multiple Salesforce Instances.
Next, we discuss Data Archival Strategies using Heroku.
Data archival strategies for keeping the Salesforce platform performant
With the span of time over the years, it’s very common that often customers end up storing large amounts of data in the Salesforce orgs! Some of which might not be even relevant at a point of time. This majorly impacts the performance of the Salesforce org.
If proper data retention policies are not in place, it is very common that one ends up storing a large volume of data in the Salesforce org. It is not a best practice and with the Data Storage limit of the org along with other limits in place it severely degrades the performance of the org.
In order to keep your Salesforce org performant and free of irrelevant data, it is always better to choose a Data Archival strategy and store the irrelevant(not in use) data outside of the Salesforce org.
Let’s look at how we can achieve a Data Archival Strategy using Heroku and Salesforce connect in the below architecture.
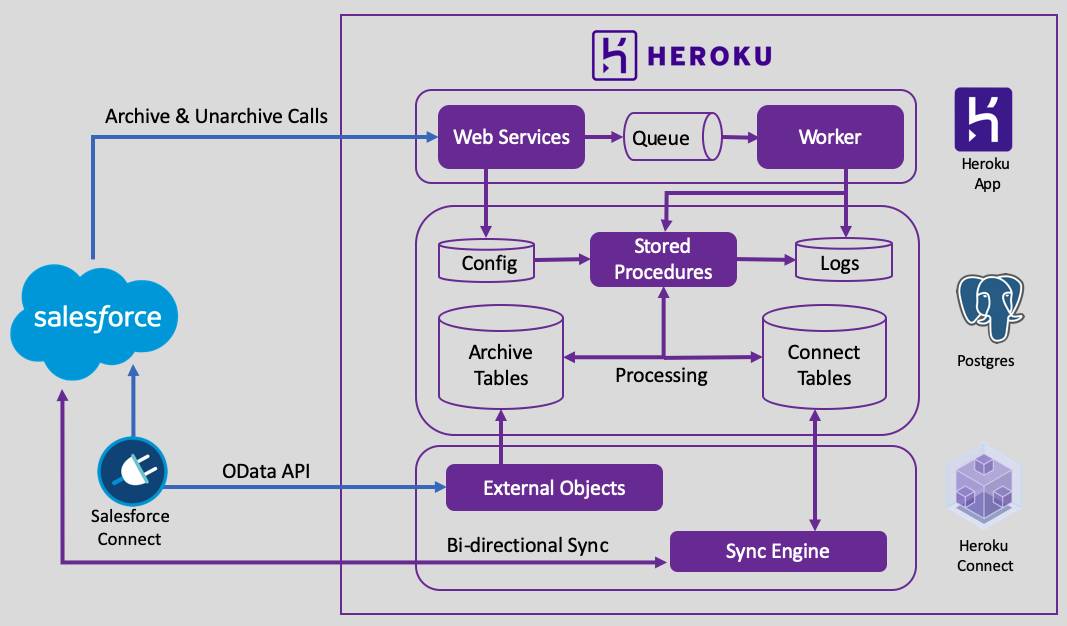
The above Architecture demonstrates how we can achieve a data archival strategy. Let’s dive into a little detail, and understand how this will work.
As shown in the above architecture, let’s first look at the Custom App(Heroku App) Component layer. We use a custom app(WebService app) hosted over the Heroku platform, which has a specific endpoint in order to receive data from external systems in our case the external system is Salesforce!! The web service provides endpoints for Salesforce to call for archiving and unarchiving records. Worker dynos are added in order to execute the process/instructions that the app receives. Dynos queue up the jobs, so it becomes an async process and completes it in the backend and finally a response is generated upon completion of the job.
Let’s now look at the PostgresDB Component. A worker running in the background calls a set of stored procedures that process all the management of records between the archive tables and the Heroku Connect tables that are live.
The third component is managed by the Heroku add-on, Heroku Connect.
Archive tables are used for storing the data which are not used any more. The Heroku connect tables store/replicate the data which are exposed via Heroku connect from the Salesforce org to the table and then processed to the archive table. In short, when a user archives a record, it is replicated and synchronized using Heroku Connect leveraging Bi-directional sync to the connect table and then later processed to the archive table.
The external objects help to expose data in the archive table by an OData endpoint which can be consumed by Salesforce Connect and in turn exposes the data back to Salesforce as an external object.
So whenever there is a need to un-archive the records, the records can be un-archived, as well as the archived records can be exposed and not stored natively in Salesforce using External Objects leveraging Salesforce Connect.
With the above architectural pattern an efficient archival solution can be developed and Implemented. With the above architectural Implementation we can expect significant performance improvements on the customers’ Salesforce org.
I hope you have learnt a little something here in this blog post, as we discussed various Heroku Architecture Design Patterns for specific use cases.
More amazing content on Heroku to follow, keep an eye on this space!!






